AI Crawlers Fall Into 3 Types Plus a Foundation | The Answer to GEO Strategy Is "All-Bot Coverage"
Bots that retrieve information from websites for AI can be classified into three types based on their purpose and timing: ① index-type, ② learning-type, and ③ proxy-access type. Underlying all of these is the traditional search engine bot as the foundational layer.
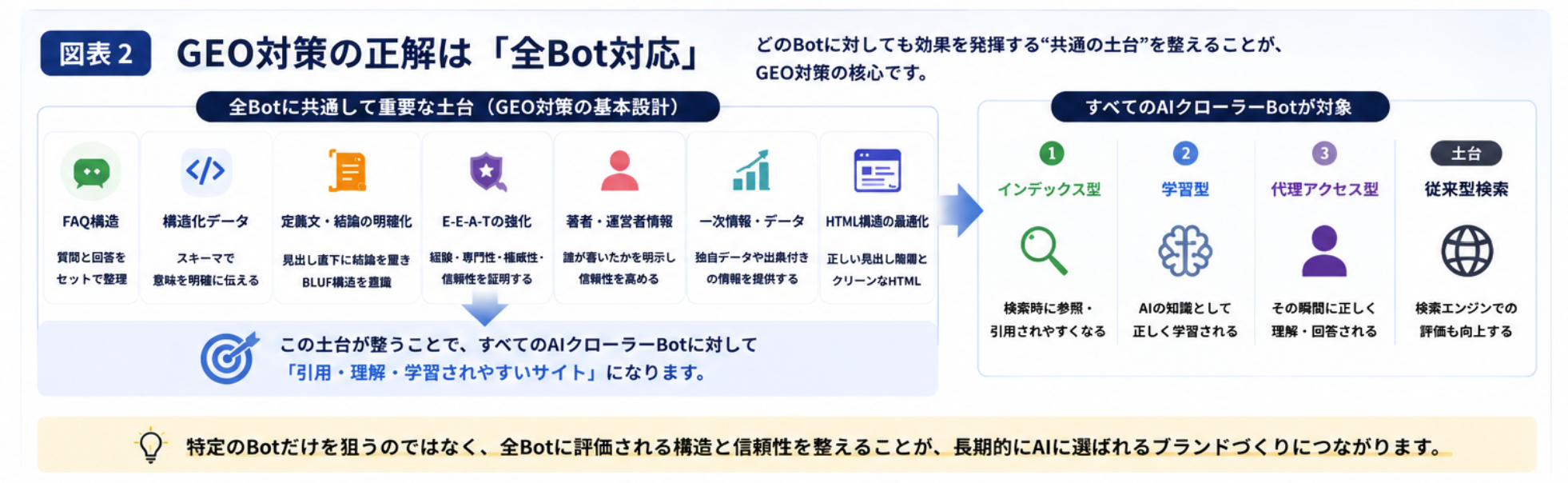
GEO strategy is not about "optimizing for a specific bot," but rather about "creating a state in which any bot can easily cite, understand, and learn from your content." In other words, the correct answer for GEO is "all-bot coverage."
This article publicly shares the "map of understanding" that I developed while building Genview. At this point, it is an organized overview based on official documentation from each company and overseas verification data. Our own verification through Genview (bot visit frequency, changes in citation rates, etc.) will be added to this article incrementally going forward.
What You Will Learn From This Article
- The "3+1" classification of AI crawler bots and how each type behaves
- The direction of strategy for each of index-type, learning-type, and proxy-access type
- Visit frequency data for each bot and findings from overseas research
- The foundational GEO strategy design that works for all bots
Why Bot Classification Is Necessary
Understanding the "why" of GEO strategy requires knowing how AI retrieves information from the web.
When you research GEO strategy, information flies around: "FAQ structure is important," "include definition statements," "implement schemas." All of this is correct, but explanations of why those measures are effective are often absent. Understanding that "why" requires knowing how AI retrieves information from the web. That is where AI crawler bots come in.
As of 2026, there are more than 10 major AI crawlers, each with completely different behaviors, purposes, and evaluation axes. Implementing measures without organizing this leaves the rationale for their effectiveness vague.
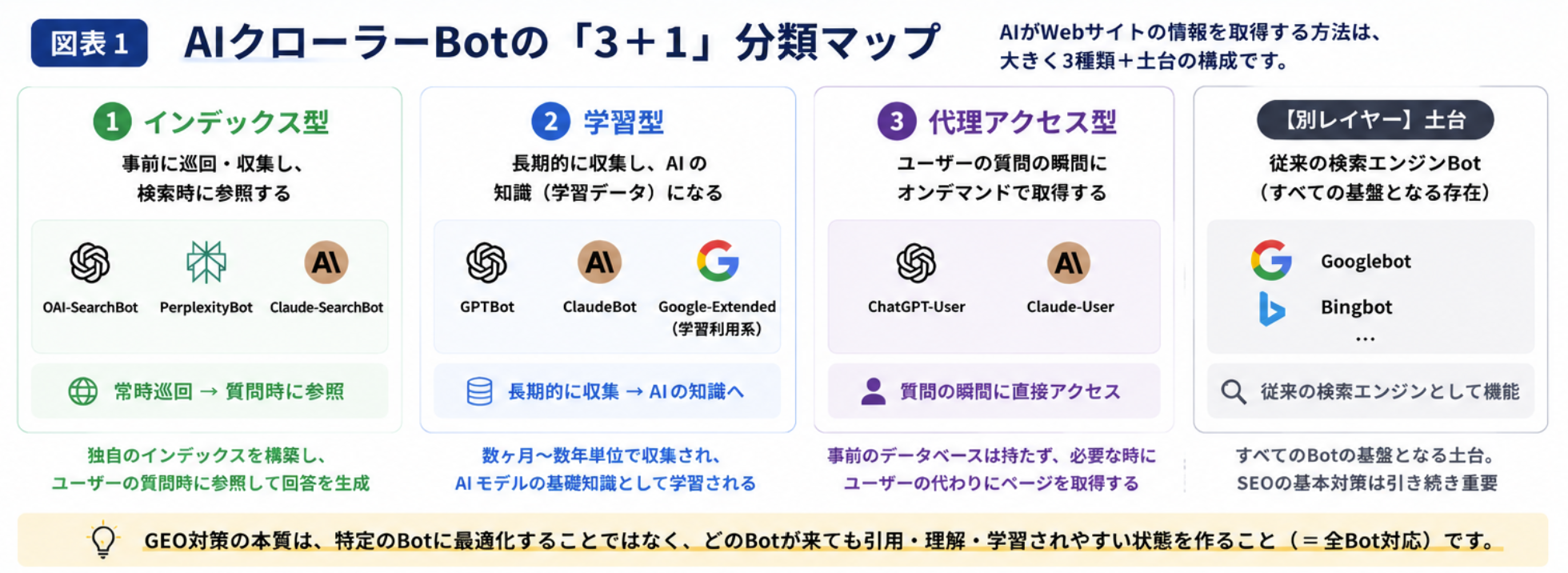
Overview of the "3+1" Classification
AI crawler bots can broadly be organized into the following four categories. Each classification is clearly distinguished by its "timing of activity" and "purpose."
The "3+1" Classification of AI Crawler Bots
| Classification |
Representative Bots |
Timing of Activity |
| ① Index-type |
OAI-SearchBot / PerplexityBot / Claude-SearchBot |
Constantly crawling → referenced at query time |
| ② Learning-type |
GPTBot / Google-Extended / ClaudeBot |
Long-term collection → becomes AI knowledge |
| ③ Proxy-access type |
ChatGPT-User / Claude-User |
On-demand retrieval at the moment of the query |
| [Separate layer] Traditional |
Googlebot / Bingbot |
Traditional search engines (the foundation of all strategy) |
The behaviors, evaluation axes, and strategic directions differ for each classification. Each is explained in detail below.
① Index-type: Pre-collected and Referenced at Query Time
OAI-SearchBot (OpenAI), PerplexityBot, and Claude-SearchBot (Anthropic) fall into this category. They constantly crawl the web before users search to build their own databases, then rapidly retrieve information from those databases to generate responses when a user poses a question.
OAI-SearchBot
OAI-SearchBot is the bot used to build the proprietary index for ChatGPT Search. As explicitly stated in OpenAI's official documentation, it is a separate bot from GPTBot, which is used for training. ChatGPT Search also employs a hybrid information retrieval approach, combining OAI-SearchBot's proprietary collection with Bing's index and real-time retrieval.
PerplexityBot (as of May 2026)
PerplexityBot is the information source for the search and answer engine operated by Perplexity AI. As of May 2026, its official description states that it is used for search indexing rather than foundational model training. (Since AI companies may change their specifications, please also verify the latest official information.)
Claude-SearchBot (as of May 2026)
As of May 2026, Anthropic's official documentation clearly classifies Claude-SearchBot as "a bot for search indexing," distinguishing its role from Claude-User, which is a proxy-access type bot.
Strategic Direction for Index-type Bots
These bots prioritize "structures that are easy to cite." Specifically, four key areas:
- BLUF (Bottom Line Up Front) structure with conclusions placed immediately below headings (H2/H3)
- FAQ format pairing questions and answers
- Primary information with clear figures and sources
- Domain credibility (citation track record and authority)
Strategy is not limited to "clean HTML text structure" — the credibility of the domain itself has a significant impact. Even with clean HTML, content from low-credibility domains tends to be less likely to be cited.
② Learning-type: Becomes AI Knowledge Over the Long Term
GPTBot (OpenAI), ClaudeBot (Anthropic), and Google-Extended (Google) fall into this category. They collect web data over months to years to train AI models as foundational knowledge (parameters).
Strictly speaking, GPTBot and ClaudeBot are independent crawlers, but Google-Extended is not a crawler itself — it is a "User-agent token that controls whether Googlebot's crawling is permitted for AI learning purposes." Although this article groups them together under "learning-related" for convenience, please note that their technical positioning differs.
Evidence From Official Documentation
- OpenAI official: Explicitly states that GPTBot is "used to make OpenAI's generative AI foundation models more helpful and safe."
- Google official: States that Google-Extended is "used for training Gemini models and Vertex AI, and for grounding AI responses."
Grok-type Bots (as of May 2026)
As of May 2026, no official documentation whatsoever has been published for Grok-type bots (xAI). It is speculated that real-time mentions and trends on X (formerly Twitter) have an influence, but details are unknown, and all information in this article about them is inference-based.
Strategic Direction for Learning-type Bots
- Site-wide expertise (hub-and-spoke structure)
- Comprehensive definition of concepts (entities)
- Author and organizational E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness)
- Logical consistency and unified terminology
Strategy for learning-type bots requires a long-term perspective focused not on "being cited right now," but on "how to become embedded in AI's knowledge."
③ Proxy-access type: Retrieves Pages at the Moment of the Query
ChatGPT-User (OpenAI) and Claude-User (Anthropic) fall into this category. Without maintaining a prior database, at the exact moment a user instructs "load this URL" in a prompt, they directly access the target page as a proxy for the user.
In February 2026, Anthropic updated its official documentation to explicitly state the three-bot structure of ClaudeBot (for learning), Claude-SearchBot (for search indexing), and Claude-User, along with the role of each bot. Of these, the proxy-access type is Claude-User, defined as "the bot that assists in accessing websites when Claude's users ask questions." Claude-SearchBot is a separate bot classified as ① index-type.
Strategic Direction for Proxy-access Type Bots
- Structure in which "the answer to that heading" appears immediately below each H2/H3 heading
- Semantic HTML that holds up even in long-form content (correct heading hierarchy)
- Body text written without JavaScript dependency
[Separate Layer] Traditional Search Engines: The Foundation of Everything
Googlebot and Bingbot are bots for traditional search engines, not AI search. However, it is known that OAI-SearchBot uses Bing's search API as a hybrid approach behind the scenes, and Perplexity and others are also understood to supplementally use Google and Bing indexes (not fully disclosed officially).
In other words, sites that have not completed traditional SEO (Googlebot strategy) may not even enter the selection pool for AI search. This is why Googlebot was separated as a "different layer."
Bot Visit Frequency: Insights From Overseas Data
How frequently does each bot visit a site? For now, we refer to overseas observational data.
Cloudflare AI Crawler Traffic Study (October–November 2025)
The following table shows data from Cloudflare's analysis of HTML requests from October to November 2025. Comparing unique page reach rates, Googlebot has an overwhelmingly larger coverage compared to other AI crawlers.
Cloudflare Study: Unique Page Reach Rate by Bot (October–November 2025)
| Bot |
Unique Page Reach Rate |
| Googlebot |
11.6% |
| GPTBot |
3.6% |
| ClaudeBot |
2.4% |
| PerplexityBot |
0.06% |
Googlebot's coverage is overwhelmingly larger compared to other AI crawlers, which is one of the bases for the positioning of "Googlebot = the foundation of all AI strategy." Source: Cloudflare AI Crawler Traffic Study (Search Engine Journal) / Original Cloudflare Blog
12-Site, 30-Day Server Log Study (March–April 2026)
The table below shows the average daily hit count per site from an overseas study analyzing server logs from 12 sites over 30 days. GPTBot leads in access frequency, followed by ClaudeBot.
12-Site, 30-Day Server Log Study: Average Daily Hit Count per Site (March–April 2026)
| Bot |
Average Daily Hit Count |
| GPTBot |
4,200 |
| ClaudeBot |
1,800 |
| PerplexityBot |
980 |
| Google-Extended |
540 |
GPTBot revisits high-traffic pages on average every 2.4 days, while ClaudeBot does so on average every 6.8 days — a significant difference in frequency. This indicates a tendency for frequently updated sites to be picked up by GPTBot first.
Rapid Growth of AI Search Traffic
Data also shows that visits via AI search grew 42.8% from 15.6 billion to 27.4 billion over the one-year period from Q1 2025 to Q1 2026. AI search is already a present and active channel, not a topic for the future.
* All of the above data are from studies targeting overseas sites. Genview is conducting its own verification regarding the actual situation for Japanese-language sites, and will add data to this article as it becomes available.
Measures That Work for All Three Classifications
While the behaviors of each bot differ, there are measures that are commonly effective for all bots. This is the foundational design of GEO strategy. The table below organizes common measures and the reasons they are effective for all bots.
GEO Measures That Work for All Bots
| Measure |
Why It Works for All Bots |
| FAQ and definition statements |
Both index-type and proxy-access type bots prefer "structures that are easy to answer from" |
| Heading (H2/H3) + conclusion placement |
All bots retrieve information on a section-by-section basis |
| Primary information with clear citations |
Both learning-type and citation-type bots have credibility as an evaluation axis |
| Semantic HTML |
Structures that convey meaning even after JS removal are effective for all bots |
| E-E-A-T and author information |
Especially important for learning-type bots. Index-type also uses it for credibility assessment |
The essence of GEO strategy is not to individually optimize "what to do for which bot," but to "create a state that can respond to any bot that arrives." Bot classification knowledge is best used as a map for understanding "why that measure is necessary."
What Genview Will Verify Going Forward
The content written in this article is an organized overview based on official documentation and overseas observational data at this point. Through the development and operation of Genview, we will conduct the following verifications in-house.
- Visit frequency of each AI crawler bot (Japanese-language sites, by scale)
- Time lag from bot visit to AI citation
- Changes in citation rates based on the presence or absence of FAQ content structure (including cases with FAQPage structured data)
- Differences in bot behavior before and after semantic HTML implementation
- Structural differences in content cited by ClaudeBot, GPTBot, and PerplexityBot
As verification data is compiled, it will be added to this article or published as a separate article. We will continue to publish with the attitude that "the people building a GEO strategy tool understand GEO most deeply."
FAQ
- Q: Does GEO strategy need to be done separately from SEO strategy?
- A: Not separately — SEO is the foundation. Pages that are not indexed by Googlebot tend to be less likely to be targeted by AI search either. The correct order is to establish an SEO foundation first, then layer GEO strategy on top of it.
- Q: Should I block bots with robots.txt?
- A: Blocking learning-type bots (GPTBot, ClaudeBot) does not affect citation in AI responses or inclusion in search results. However, blocking index-type bots (OAI-SearchBot, PerplexityBot) will result in exclusion from ChatGPT Search and Perplexity search results. It is recommended to configure settings individually based on your objectives.
- Q: How is PerplexityBot different from Google and Bing?
- A: Googlebot and Bingbot are bots for traditional search engines that return search result links to users. PerplexityBot collects information for AI response generation and is displayed as a citation URL within the response — which is the key difference. Since it is explicitly presented as a citation source, it tends to have a direct connection to click-through traffic.